
7 月 4 日,中國雷鋒網發表了一篇文章「致 IBM Watson:六年過去,昔日的人工智能老大哥你還好嗎?」其中特別強調 MIT 科技評論提到的「IBM Watson 在醫療人工智慧的進展緩慢,難堪大用。」而最近 Google 台灣也特別找來矽谷總部的彭浩怡醫學博士, 對外講解 它在醫學上怎麼應用深度學習,來達成糖尿病視網膜病變辨識與淋巴結中的乳腺癌的轉移瘤的視覺辨識。

在 2012 年 IBM Watson 在 Jeopardy 益智遊戲戰勝兩名美國的常勝冠軍後,就轉往了醫療方面。而 2015 年,更買下了 AlchemyAPI,來強化其深度學習能力,目前它已經在六種腫瘤上做訓練,今年還打算再增加八種。但是,MD 安德森癌症中心,今年也決定跟 IBM Watson 分道揚鑣。
難道 IBM Watson 真的不行了嗎?這其實是因為深度學習需要大量符合需求的有效資料,才能把深度學習的類神經網路各階層的參數,在模型中學習到正確且完整。而如何得到夠多而符合需求的資料,則是在醫療資料獲取過程中,相對艱難的部分,尤其很多資料獲取並不是那麼容易得到足夠的數量。
針對影像識別的人工智慧應用,現在的做法是透過卷積深度學習來訓練,如同 Google 彭博士在這次演講中說到,Tensorflow 只需要 5000 張同一種類照片與 5000 張非此種類照片就可以(演講中以熊貓為例),就可以做到識別。
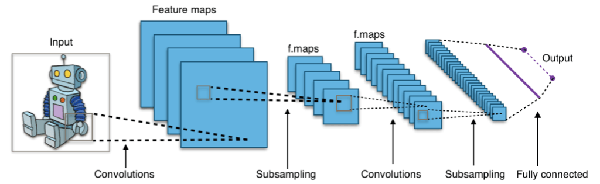
圖:彭博士提的深度學習卷積網路的例圖 來源:commons.wikimedia.org 作者:Aphex34
彭博士所做的糖尿病視網膜病變的影像,因為直接攝影容易,影像數量夠多(128000 張),也因此得到不錯的模型。但是高解析度的淋巴結中的乳腺癌的轉移瘤處理過的切片顯微鏡下的照片,就得多花時間處理。整個過程中,都需要跟專科醫生們合作,以人工辨識確認效果好壞,往往來回多次,很耗時間。而且,還往往可能有不同格式需轉成同樣格式的困擾。也因此,Google 希望透過醫療開放數據標準,以讓醫界人士達成更容易使用這些數據。不過,這不是短時間可以達成的。
這其實也就能解釋為什麼 Watson 的效果不如預期了。資料蒐集的難度,包含資料格式的不一致,資料的清洗與處理以去除假資料,隱私權造成資料蒐集的障壁,讓步調緩慢,使整個被訓練到夠好的癌症診斷的深度學習模型不如預期的多,相對成長速度太慢,這很可能就是 MD 安德森癌症中心不再合作的主因。
深度學習最大的缺點就是需要很大量的正確的資料,才能把監督式學習的模型較完整地完成,以現在的進度發展的確不夠快。但假以時日,透過越來越多種類的病症資料蒐集足夠且品質良好,就可以讓深度學習發揮更大的效能,以幫助人類醫生做更正確的診療。

![Read more about the article [專案經理雜誌文章]影響我們行的 生活之智慧交通](https://www.rich4innovation.com.tw/wp-content/uploads/2020/08/Z_Art_085991340.png)